
A practical framework for diagnosing sensor faults, PLC issues, communication failures, and recovery priorities in pharmaceutical and controlled environments.

When a monitoring system fails, the issue is no longer only technical. It becomes a compliance, data integrity, and production continuity problem.
Cleanroom MOPS troubleshooting is a structured process for identifying, diagnosing, and resolving failures across sensors, data acquisition, communication, software, and power layers. A strong recovery framework helps teams minimize downtime, maintain reliable environmental oversight, and protect GMP decision-making during system instability.
Cleanroom MOPS troubleshooting is a structured process used to identify, diagnose, and resolve failures in monitoring systems, including sensors, PLCs, communication networks, and software layers. It helps maintain continuous environmental visibility, protect data integrity, and support GMP-compliant decision-making in pharmaceutical cleanrooms.
The biggest risk is not just equipment failure. It is delayed decisions, incomplete visibility, weak documentation, and uncertainty in critical areas.
Monitoring loss can rapidly affect zone release logic and manufacturing continuity.
Unstable systems create gaps in records and make trending less defensible.
Without a recovery SOP, teams struggle to justify continued operation or containment actions.
Cross-functional teams lose time when symptoms are not mapped to a clear troubleshooting model.
This page is designed as a practical reference for MOPS engineers, maintenance teams, QA, and validation professionals who need a faster and more consistent path from system symptom to defensible recovery decision.
A cleanroom monitoring system failure occurs when any component of the environmental monitoring system—such as sensors, PLCs, communication infrastructure, or software—fails to provide accurate, continuous, or reliable data required for GMP-controlled operations.
Loss of visibility can affect environmental control decisions, deviation handling, batch-release logic, and the defensibility of GMP documentation.
Separating failures by system layer helps teams identify which events need immediate production or quality escalation and which can be managed through structured technical recovery.
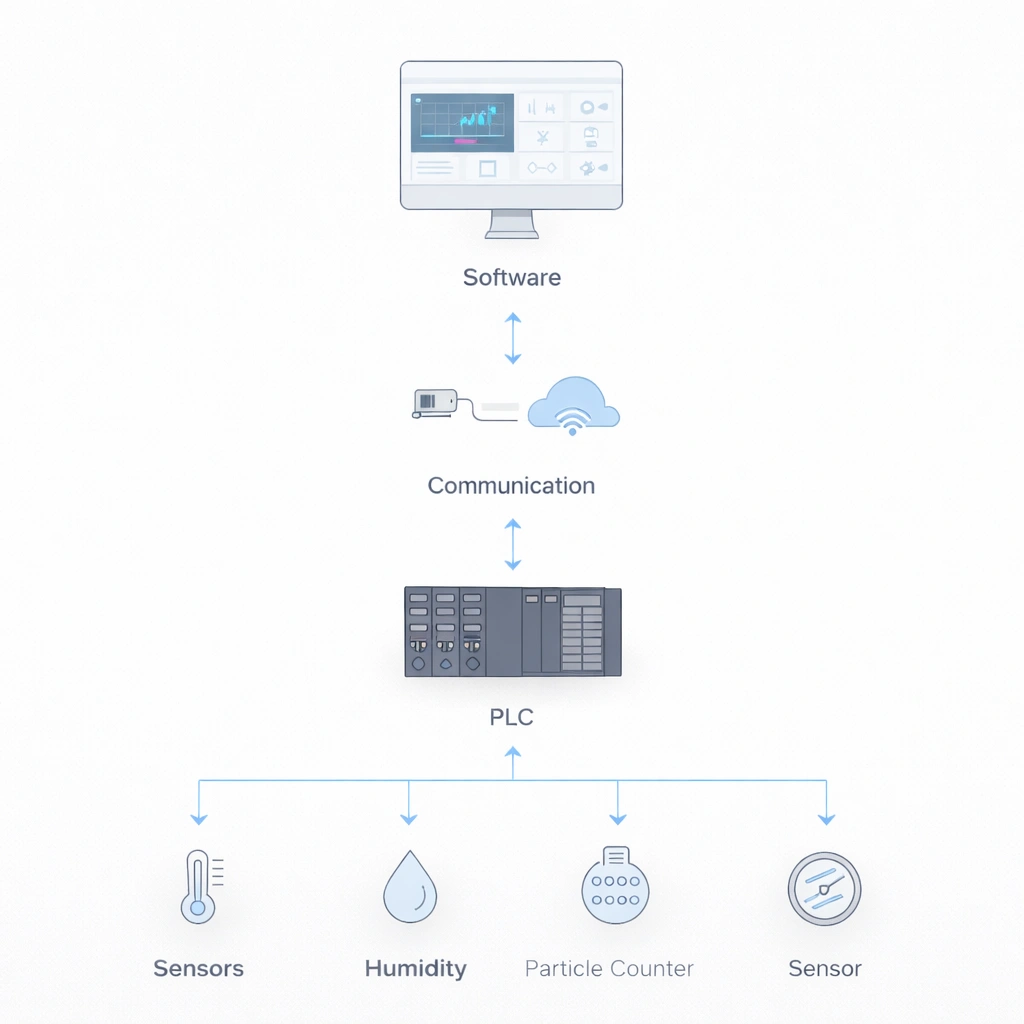
| System Layer | Components | Failure Impact | Recovery Priority |
|---|---|---|---|
| Sensors Layer | Particle counters, microbial samplers, pressure sensors, temperature / humidity probes | Direct impact on monitoring data quality | Critical – P1 |
| Data Acquisition | PLCs, data loggers, signal converters | Data loss or corruption risk | Critical – P1 |
| Communication Layer | Network switches, cabling, wireless modems | System isolation and visibility loss | High – P2 |
| Software Layer | SCADA / HMI, database, reporting applications | Analysis paralysis and delayed response | Medium – P3 |
| Power Layer | UPS, surge protectors, wiring distribution | Complete system shutdown | Critical – P1 |
Use a simple decision layer to determine whether the event can be contained locally or requires emergency recovery action.
| Situation | Recommended Action | Production Impact |
|---|---|---|
| Single sensor failure | Switch to backup or validated manual monitoring and document evidence. | کم |
| Multiple sensor failure | Investigate PLC, communication path, and shared infrastructure immediately. | میڈیم |
| Full system failure | Activate emergency containment and defined recovery protocol. | اعلی |
Use a consistent sequence so every event moves from symptom to verified recovery without skipping root-cause logic or documentation discipline.
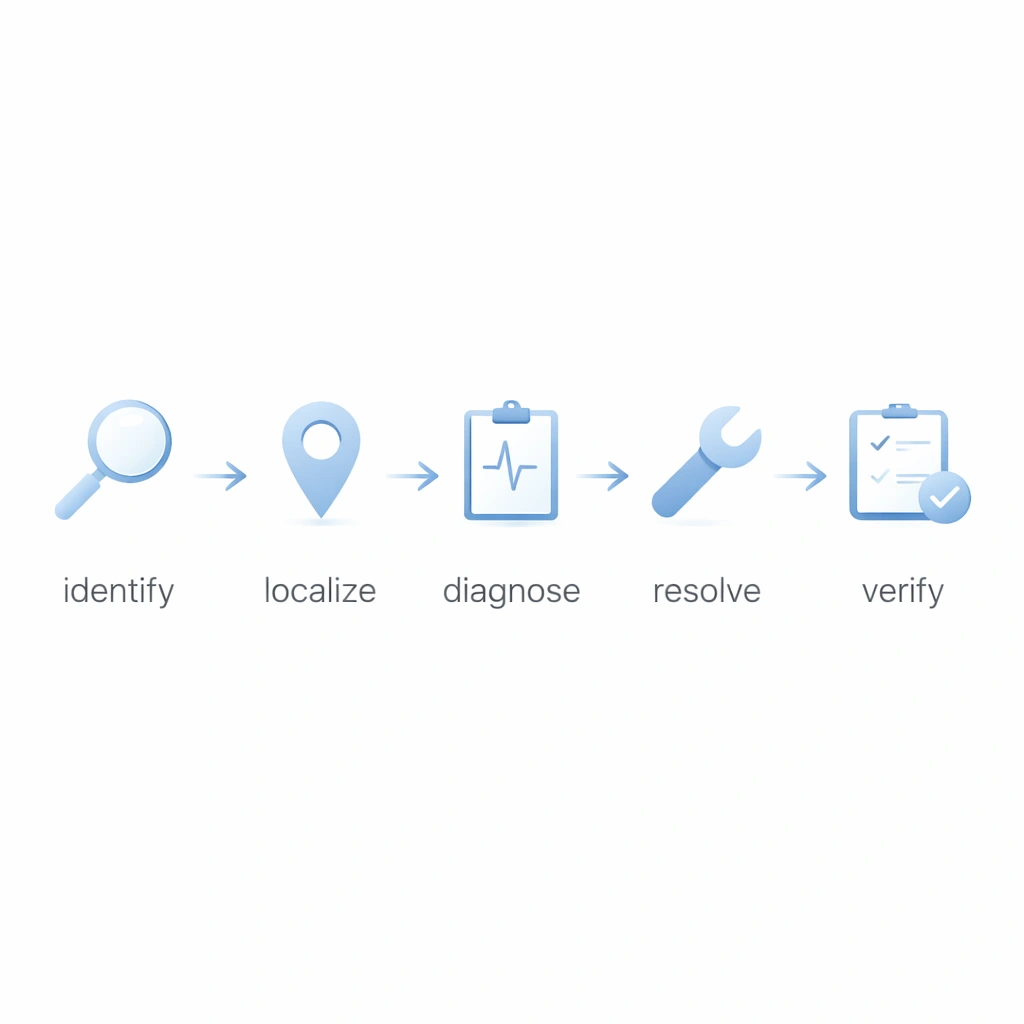
Confirm the visible symptom, affected zone, timestamp, system layer, and initial business impact.
Narrow the failure to the likely component set: sensor, PLC, communication, software, or power.
Run targeted tests instead of broad trial-and-error checks. Capture the evidence used to support each conclusion.
Execute the appropriate corrective action, isolate any unstable components, and define temporary containment if needed.
Monitor the recovered system, confirm normal performance, and close the event with documented follow-up logic.
Sensor issues are often the first visible sign of monitoring instability. The goal is to separate temporary signal issues from true hardware failure without overreacting or delaying escalation.
| Problem | Immediate Action | Preventive Measure |
|---|---|---|
| Zero reading | Check laser source and clean alignment window | Define cleaning checks for the alignment window |
| Maximum reading | Verify sensor condition and firmware status | Quarterly sensor health review |
| Communication timeout | Inspect cable integrity and damaged segments | Use industrial-grade shielded cabling |
| Calibration failure | Perform in-situ calibration and drift assessment | Accelerated calibration for high-use areas |
In a pharmaceutical cleanroom, loss of monitoring data does not only affect system performance. It directly affects batch-release decisions, deviation investigations, and the ability of QA to verify environmental control during manufacturing.
This is why troubleshooting SOPs must include recovery logic—not only fault detection.
This is where many teams discover they have procedures for alerts, but not a practical SOP for system recovery.
Use symptom-led testing to distinguish signal blockage, drift, calibration issues, and hardware failure.
Prioritize control-state visibility, module integrity, and error-code review before deciding on reset or replacement.

Check network tester output, cable integrity, port status, and the continuity of the monitoring data path.


Midposi is not only about alert response or cleanroom consumables. The stronger positioning is helping teams build more reliable contamination-control workflows around monitoring, response discipline, and system recovery.
Support diagnostics, containment, and restoration logic.
Strengthen traceability and GMP-facing recovery records.
Reduce downtime through prioritized recovery decisions.
Standardize how teams respond to system instability.
See how alert classification and escalation logic connects with system recovery.
Use a stronger validation backbone when troubleshooting affects monitoring confidence.
Connect system reliability with risk-based monitoring strategy across critical spaces.
Build a clearer operational framework around routine monitoring and escalation.
Strengthen qualification and recovery verification after system instability.
Connect monitoring-system reliability to a broader contamination control strategy.
Cleanroom monitoring system troubleshooting is a critical component of modern contamination control strategies, helping pharmaceutical manufacturers maintain reliable data, regulatory compliance, and operational continuity when environmental monitoring systems become unstable.
Talk to Midposi about troubleshooting frameworks, recovery SOP logic, contamination-control workflows, and practical support for controlled-environment operations.


 Optimized by Seraphinite Accelerator
Optimized by Seraphinite Accelerator